아이템 19. knowledge를 반복하여 사용하지 말라
"프로젝트에서 이미 있던 코드를 복사해서 붙여넣고 있다면, 무언가가 잘못된 것이다."
우리 프로그램에서 중요한 knowledge를 크게 두 가지 뽑는다면, 다음과 같습니다.
1. 로직 (logic): 프로그램이 어떠한 식으로 동작하는지와 프로그램이 어떻게 보이는지
2. 공통 알고리즘 (Common Algorithm): 원하는 동작을 하기 위한 알고리즘
둘의 가장 큰 차이점은 시간에 따른 변화입니다. 비즈니스 로젝은 시간이 지나면서 계속해서 변하지만, 공통 알고리즘은 한 번 정의된 이후에는 크게 변하지 않습니다. 물론 공통 알고리즘을 최적화를 하거나, 같은 카테고리의 더 빠른 알고리즘으로 바꿀 수도 있지만, 동작은 크게 변하지 않습니다.
핵심은 프로그래밍은 지속해서 변화한다는 것입니다.
UI 디자인과 기술 표준 등은 훨씬 빠르게 변화하며 고객에 대한 이해도 매일매일 변화합니다.
- 회사가 사용자의 요구 또는 습관을 더 많이 알게 되었다.
- 디자인 표준이 변화했다.
- 플랫폼, 라이브러리, 도구 등이 변화해서 이에 대응해야 한다.
ex) 슬랙은 글리치라는 온라인 게임이었지만 소비자들이 게임의 커뮤니케이션 방식을 굉장히 마음에 들어했고 지금의 형태로 변화했다.
SRP
아이템 20. 일반적인 알고리즘을 반복해서 구현하지 말라
많은 개발자는 같은 알고리즘을 여러 번 반복해서 구현합니다.
val percent = when {
numberFromUser > 100 -> 100
numberFromUser < 0 -> 0
else -> numberFromUser
}이 알고리즘은 사실 stdlib의coerceIn 확장 함수로 이미 존재합니다. 따라서 따로 구현하지 않아도 됩니다.
val percent = numberFromUser.coerceIn(0, 100)
이렇게 이미 있는 것을 활용하면, 단순하게 코드가 짧아진다는 것 이외에도 다양한 장점이 있습니다.
- 코드 작성 속도 향상
- 함수의 이름 등만 보고도 무엇을 하는지 확실하게 알 수 있다.
- 직접 구현할 때 발생할 수 있는 실수를 줄일 수 있다.
표준 라이브러리 살펴보기
일반적인 알고리즘은 대부분 이미 다른 사람들이 정의해 놓았습니다. 그 중에서 가장 대표적인 라이브러리는 바로 표준 라이브러리인 stdlib입니다. stdlib은 확장 함수를 활용해서 만들어진 굉장히 거대한 유틸리티 라이브러리입니다.
override fun saveCallResult(item: SourceResponse) {
var sourceList = ArrayList<SourceEntity>()
items.sources.forEach {
var sourceEntity = SourceEntity()
sourceEntity.id = it.id
sourceEntity.category = it.category
sourceEntity.country = it.country
sourceEntity.description = it.description
sourceList.add(sourceEntity)
}
db.insertSources(sourceList)
}
앞의 코드에서 forEach를 사용하는 것은 사실 좋지 않습니다. 이러한 코드는 for 반복문을 사용하는 것보다는 map 함수를 사용하면 됩니다. 또한 현재 코드에서는 SourceEntity를 설정하는 부분이 어설픕니다. 이는 코틀린으로 작성된 코드에서 더 이상 찾아볼 수 없는 자바빈 (JavaBean) 패턴입니다. 이런 형태보다는 팩토리 메서드를 활용하거나, 기본 생성자를 사용하는 것이 좋습니다. 그래도 위와 같은 패턴을 써야겠다면, 다음과 같이 최소한 apply를 활용해서 모든 단일 객체들의 프로퍼티를 암묵적으로 설정하는 것이 좋습니다.
override fun saveCallResult(items: SourceResponse) {
val sourceEntries = item.sources.map(::sourceToEntry)
db.insertSources(sourceEntries)
}
private fun sourceToEntry(source: Source) = SourceEntity()
.apply {
id = source.id
category = source.category
country = source.country
description = source.description
}
나만의 유틸리티 구현하기
상황에 따라서 표준 라이브러리에 없는 알고리즘이 필요할 수도 있습니다. 예를 들어 컬렉션에 있는 모든 숫자의 곱을 계산하는 라이브러리가 필요하다면 어떻게 해야 할까요? 이는 널리 알려진 추상화이므로 범용 유틸리티 함수 (universal utility function)로 정의하는 것이 좋습니다.
fun Iterable<Int>.product() = fold(1) { acc, i -> acc * i }여러 번 사용되지 않는다고 해도 이렇게 만드는 것이 좋습니다. 이는 잘 알려진 수학적 개념이고, product라는 이름이 숫자를 곱할 거라는 것은 대부분의 개발자들이 예측할 수 있기 때문입니다. 이후에 다른 개발자가 컬렉션의 숫자를 곱하는 함수를 만들어야 할 때, 이렇게 이미 구현되어 있다면 기쁠 것입니다.
코틀린 stdlib에 정의된 대부분의 함수처럼, 앞 코드의 product도 확장 함수로 구현되어 있습니다. 많이 사용되는 알고리즘을 추출하는 방법으로는 톱레벨 함수, 프로퍼티 위임, 클래스 등이 있습니다. 확장 함수는 이러한 방법들과 비교해서, 다음과 같인 장점을 갖고 있습니다.
- 함수는 상태를 유지하지 않으므로, 행위를 나타내기 좋습니다. 특히 부가 작용 (side-effect)이 없는 경우에는 더 좋습니다.
- 톱레벨 함수와 비교해서, 확장 함수는 구체적인 타입이 있는 객체에만 사용을 제한할 수 있으므로 좋습니다.
- 수정할 객체를 아규먼트로 전달받아 사용하는 것보다는 확장 리시버로 사용하는 것이 가독성 측면에서 좋습니다.
- 확장 함수는 객체에 정의한 함수보다 객체를 사용할 때, 자동 완성 기능 등으로 제안이 이루어지므로 쉽게 찾을 수 있습니다. ex) TextUtils.isEmpty("Text")보다는 "Text".isEmpty()가 더 사용하기 쉽습니다.
아이템21. 일반적인 프로퍼티 패턴은 프로퍼티 위임으로 만들어라
코틀린은 코드 재사용과 관련해서 프로퍼티 위임이라는 새로운 기능을 제공합니다. ex) lazy
프로퍼티 위임을 사용하면, 이외에도 변화가 있을 때 이를 감지하는 observable 패턴을 쉽게 만들 수 있습니다.
val items: List<Item> by Delegates.observable(listOf()) { _, _, _ ->
notifyDataSetChanged()
}
var key: String? by Delegates.observable(null) { _, old, new ->
Log.e("key changed from $old to $new")
}lazy와 observable 델리게이터는 언어적인 관점에서 보았을 때, 그렇게 특별한 것은 아닙니다. 일반적으로 프로퍼티 위임 메커니즘을 활용하면, 다양한 패턴들을 만들 수 있습니다. 좋은 예로 뷰, 리소스 바인딩, 의존성 주입, 데이터 바인딩 등이 있습니다. 일반적으로 이런 패턴들을 사용할 때 자바 등에서는 어노테이션을 많이 활용해야 합니다. 하지만 코틀린은 프로퍼티 위임을 사용해서 간단하고 type-safe하게 구현할 수 있습니다.
간단한 프로퍼티 델리게이트를 만들어보겠습니다.
var token: String? = null
get() {
print("token returned value $field")
return field
}
set(value) {
print("token changed from $field to $value")
field = value
}
var attempts: Int = 0
get() {
print("attempts returned value $field")
return field
}
set(value) {
print("attempts changed from $field to $value")
field = value
}
두 프로퍼티는 타입이 다르지만, 내부적으로 거의 같은 처리를 합니다. 또한 프로젝트에서 자주 반복될 것 같은 패턴처럼 보입니다. 따라서 프로퍼티 위임을 활용해서 추출하기 좋은 부분입니다. 프로퍼티 위임은 다른 객체의 메서드를 활용해서 프로퍼티의 접근자 (게터와 세터)를 만드는 방식입니다. 이때 다른 객체의 메서드 이름이 중요한데요. 게터는 getValue, 세터는 setValue 함수를 사용해서 만들어야 합니다. 객체를 만든 뒤에는 by 키워드를 사용해서, getValue와 setValue를 정의한 클래스와 연결해주면 됩니다.
var token: String? by LoggingProperty(null)
var attempts: Int by LoggingProperty(0)
private class LoggingProperty<T>(var value: T) {
operator fun getValue(
thisRef: Any?,
prop: KProperty<*>
): T {
print("${prop.name} returned value $value")
return value
}
operator fun setValue(
thisRef: Any?,
prop: KProperty<*>,
newValue: T
) {
val name = prop.name
print("$name changed from $value to $newValue")
value = newValue
}
}
프로퍼티 위임이 어떻게 동작하는지 이해하려면, by가 어떻게 컴파일되는지 보는 것이 좋습니다. 위의 코드에서 token 프로퍼티는 다음과 비슷한 형태로 컴파일됩니다.
@JvmField
private val 'token$delegate' = LoggingProperty<String?>(null)
var token: String?
get() = 'token$delegate'.getValue(this, ::token)
set(value) {
'token$delegate'.setValue(this, ::token, value)
}코드를 보면 알 수 있는 것처럼 getValue와 setValue는 단순하게 값만 처리하게 바뀌는 것이 아니라, 컨텍스트(this)와 프로퍼티 레퍼런스의 경계도 함께 사용하는 형태로 바뀝니다. 프로퍼티에 대한 레퍼런스는 이름, 어노테이션과 관련된 정보 등을 얻을 때 사용됩니다. 그리고 컨텍스트는 함수가 어떤 위치에서 사용되는지와 관련된 정보를 제공해줍니다.
이러한 정보로 인해서 getValue와 setValue 메서드가 여러 개 있어도 문제가 없습니다. getValue와 setValue 메서드가 여러 개 있어도 컨텍스트를 활용하므로, 상황에 따라서 적절한 메서드가 선택됩니다. 이는 굉장히 다양하게 활용됩니다. 예를 들어 여러 종류의 뷰와 함께 사용할 수 있는 델리게이트가 필요한 경우를 생각해 봅시다. 이는 다음과 같이 구현해서, 컨텍스트의 종류에 따라서 적절한 메서드가 선택되게 만들 수 있습니다.
class SwipeRefreshBinderDelegate(val id: Int) {
private var cache: SwipeRefreshLayout? = null
operator fun getValue(
activity: Activity,
prop: KProperty<*>
): SwipeRefreshLayout {
return cache ?: activity
.findViewById<SwipeRefreshLayout>(id)
.also { cache = it }
}
operator fun getValue(
fragment: Fragment
): SwipeRefreshLayout {
return cache ?: fragment.view
.findViewById<SwipeRefreshLayout>(id)
.also { cache = it }
}
}
객체 프로퍼티를 위임하려면 val의 경우 getValue 연산, var의 경우 getValue와 setValue 연산이 필요합니다. 이러한 연산은 지금까지 살펴본 것처럼 멤버 함수로도 만들 수 있지만, 확장 함수로도 만들 수 있습니다. 예를 들어 다음 코드는 Map<String, *>를 사용하는 예입니다.
val map: Map<String, Any> = mapOf(
"name" to "Marcin",
"kotlinProgrammer" to true
)
val name by map
print(name) // Marcin
이는 코틀린 stdlib에 다음과 같은 확장 함수가 정의되어 있어서 사용할 수 있는 것 입니다.
inline operator fun <V, V1 : V> Map<in String, V>
.getValue(thisRef: Any?, property: KProperty<*>): V1 =
getOrImplicitDefault(property.name) as V1
코틀린 stdlib에서 다음과 같은 프로퍼티 델리게이터를 알아두면 좋습니다.
- lazy
- Delegates.observable
- Delegates.vetoable
- Delegates.notNull
아이템 22. 일반적인 알고리즘을 구현할 때 제네릭을 사용하라.
아규먼트로 함수에 값을 전달할 수 있는 것처럼, 타입 아규먼트를 사용하면 함수에 타입을 전달할 수 있습니다. 타입 아규먼트를 사용하면 함수에 타입을 전달할 수 있습니다. 타입 아규먼트를 사용하는 함수 (즉, 타입 파라미터를 갖는 함수)를 제네릭 함수라고 부릅니다. 대표적인 예로는 stdlib에 있는 filter 함수가 있습니다. filter 함수는 타입 파라미터 T를 갖습니다.
inline fun <T> Iterable<T>.filter(
predicate: (T) -> Boolean
): List<T> {
val destination = ArrayList<T>()
for (element in this) {
if (predicate(element)) {
destination.add(element)
}
}
}
타입 파라미터는 컴파일러에 타입과 관련된 정보를 제공하여 컴파일러가 타입을 조금이라도 더 정확하게 추측할 수 있게 해 줍니다. 따라서 프로그램이 조금 더 안전해지고, 개발자는 프로그래밍이 편해집니다. 예를 들어 filter 함수에서 람다 표현식 내부를 생각해 봅시다. 컴파일러가 아규먼트가 컬렉션의 요소와 같은 타입이라는 것을 알 수 있으므로, 잘못 처리하는 것을 막을 수 있습니다.
variance 한정자?
제네릭 제한
타입 파라미터의 중요한 기능 중 하나는 구체적인 타입의 서브타입만 사용하게 타입을 제한하는 것입니다.
fun <T: Comparable<T>> Iterable<T>.sorted(): List<T> {
/*...*/
}
fun <T, C: MutableCollection<in T>>
Iterable<T>.toCollection(destination: C): C {
/*...*/
}
Class ListAdapter<T: ItemAdapter>(/*...*/) { /*...*/ }타입에 제한이 걸리므로, 내부에서 해당 타입이 제공하는 메서드를 사용할 수 있습니다. 예를 들어 T를 Iterable<Int>의 서브타입으로 제한하면, T 타입을 기반으로 반복 처리가 가능하고, 반복 처리 때 사용되는 객체가 Int라는 것을 알 수 있습니다. 많이 사용하는 제한으로는 Any가 있습니다. 이는 nullable이 아닌 타입을 나타냅니다.
inline fun <T, R : Any> Iterable<T>.mapNotNull(
transform: (T) -> R?
): List<R> {
return mapNotNullTo(ArrayList<R>(), transform)
}드물지만 다음과 같이 둘 이상의 제한을 걸 수도 있습니다.
fun <T: Animal> pet(animal: T) where T: GoodTempered {
/*...*/
}
// 또는
fun <T> pet(animal: T) where T: Animal, T: GoodTempered {
/*...*/
}
아이템23. 타입 파라미터의 섀도잉을 피하라
다음 코드처럼 프로퍼티와 파라미터가 같은 이름을 가질 수 있습니다. 이렇게 되면 지역 파라미터가 외부 스코프에 있는 프로퍼티를 가립니다. 이를 섀도잉이라고 부릅니다.
이것은 개발자들도 문제가 있을 경우 쉽게 찾을 수 있는 부분이라 어떠한 경고도 발생시키지 않습니다.
class Forest(val name: String) {
fun addTree(name: String) {
// ...
}
}
그리고 이러한 섀도잉 현상은 클래스 타입 파라미터와 함수 타입 파라미터 사이에서도 발생합니다. 개발자가 제네릭을 제대로 이해하지 못할 때, 이와 관련된 다양한 문제들이 발생합니다. 하지만 이는 심각한 문제가 될 수 있으며, 개발자가 스스로 문제를 찾아내기도 힘듭니다.
interface Tree
class Birch: Tree
class Sqruce: Tree
class Forest<T: Tree> {
fun <T: Tree> addTree(tree: T) {
// ...
}
}
이렇게 코드를 작성하면, Forest와 addTree의 타입 파라미터가 독립적으로 동작합니다.
val forest = Forest<Birch>()
forest.addTree(Birch())
forest.addTree(Spruce())
이러한 상황을 의도하는 경우는 거의 없을 것입니다. 또한 코드만 봐서는 둘이 독립적으로 동작한다는 것은 빠르게 알아내기 힘듭니다. 따라서 addTree가 클래스 타입 파라미터인 T를 사용하게 하는 것이 좋습니다.
class Forest<T: Tree> {
fun addTree(tree: T) {
// ...
}
}
// Usage
val forest = Forest<Birch>()
forest.addTree(Birch())
forest.addTree(Sqruce()) // ERROR, type mismatch
만약 독립적인 타입 파라미터를 의도했다면, 이름을 아예 다르게 다는 것이 좋습니다. 참고로, 다음 코드처럼 타입 파라미터를 사용해서 다른 타입 파라미터에 제한을줄 수도 있습니다.
class Forest<T: Tree> {
fun <ST: T> addTree(tree: ST) {
// ...
}
}
아이템 24. 제네릭 타입과 variance 한정자를 활용하라
다음과 같은 제네릭 클래스가 있다고 합시다.
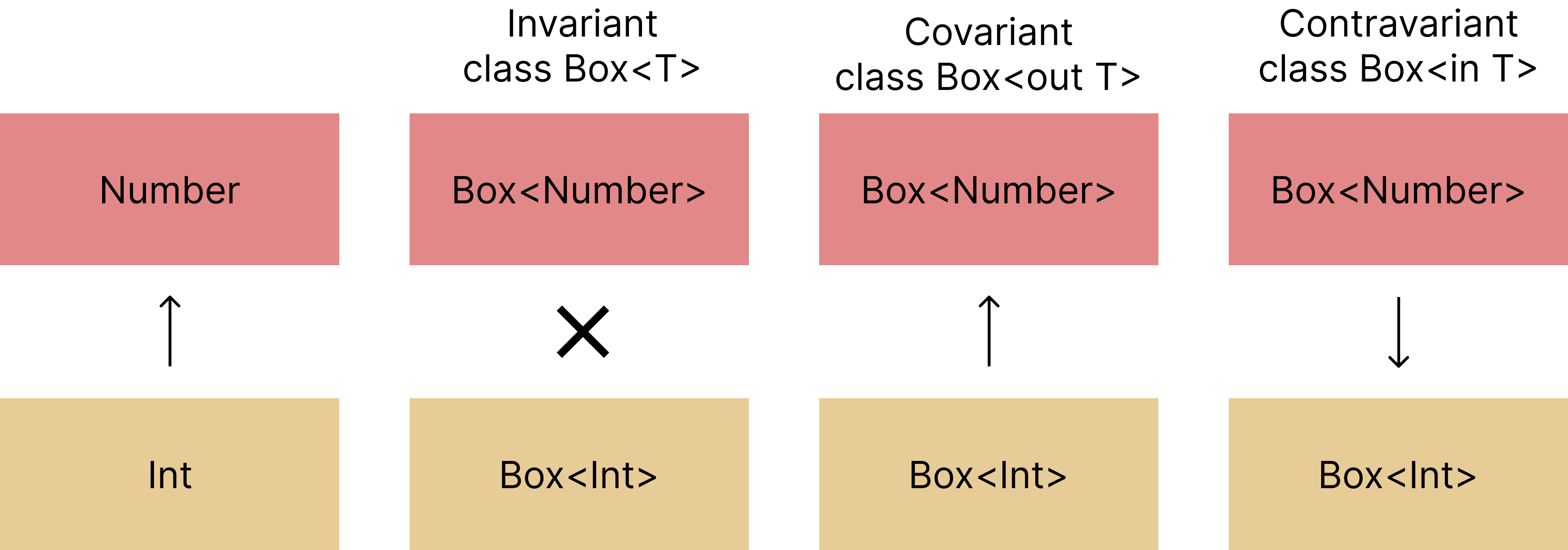
class Cup<T>위의 코드에서 타입 파라미터 T는 variance 한정자 (out 또는 in)가 없으므로, 기본적으로 invariant(불공변성)입니다. invariant라는 것은 제네릭 타입으로 만들어지는 타입들이 서로 관련성이 없다는 의미입니다. 예를 들어 Cup<Int>와 Cup<Number>, Cup<Any>와 Cup<Nothing>은 어떠한 관련성도 갖지 않습니다.
fun main() {
val anys: Cup<Any> = Cup<Int>() // 오류: Type mismatch
val nothings: Cup<Nothing> = Cup<Int>() // 오류
}
만약에 어떤 관련성을 원한다면, out 또는 in이라는 variance 한정자를 붙입니다. out은 타입 파라미터를 convariant(공변성)로 만듭니다. 이는 A가 B의 서브타입일 때, Cup<A>가 Cup<B>의 서브타입이라는 의미입니다.
class Cup<out T>
open class Dog
class Puppy: Dog()
fun main(args: Array<String>) {
val b: Cup<Dog> = Cup<Puppy>() // OK
val a: Cup<Puppy> = Cup<Dog>() // 오류
val anys: Cup<Any> = Cup<Int>() // OK
val nothings: Cup<Nothing> = Cup<Int>() // 오류
}in 한정자는 반대 의미입니다. in 한정자는 타입 파라미터를 contravaiant(반변성)으로 만듭니다. 이는 A가 B의 서브타입일 때, Cup<A>가 Cup<B>의 슈퍼타입이라는 것을 의미합니다.
class Cup<in T>
open class Dog
class Puppy(): Dog()
fun main(args: Array<String>) {
val b: Cup<Dog> = Cup<Puppy>() // 오류
val a: Cup<Puppy> = Cup<Dog>() // OK
val anys: Cup<Any> = Cup<Int>() // 오류
val nothings: Cup<Nothing> = Cup<Int>() // OK
}
함수 타입
함수타입은 파라미터 유형과 리턴 타입에 따라서 서로 어떤 관계를 갖습니다. 예를 들어 Int를 받고 Any를 리턴하는 함수를 파라미터로 받는 함수를 생각해봅시다.
fun printProcessedNumber(transition: (Int)-> Any) {
print(transition(42))
}(Int) -> Any 타입의 함수는 (Int) -> Number, (Number) -> Any, (Number) -> Number, (Number) -> Int 등으로도 작동합니다.
이는 이러한 타입들에 다음과 같은 관계가 있기 때문입니다.
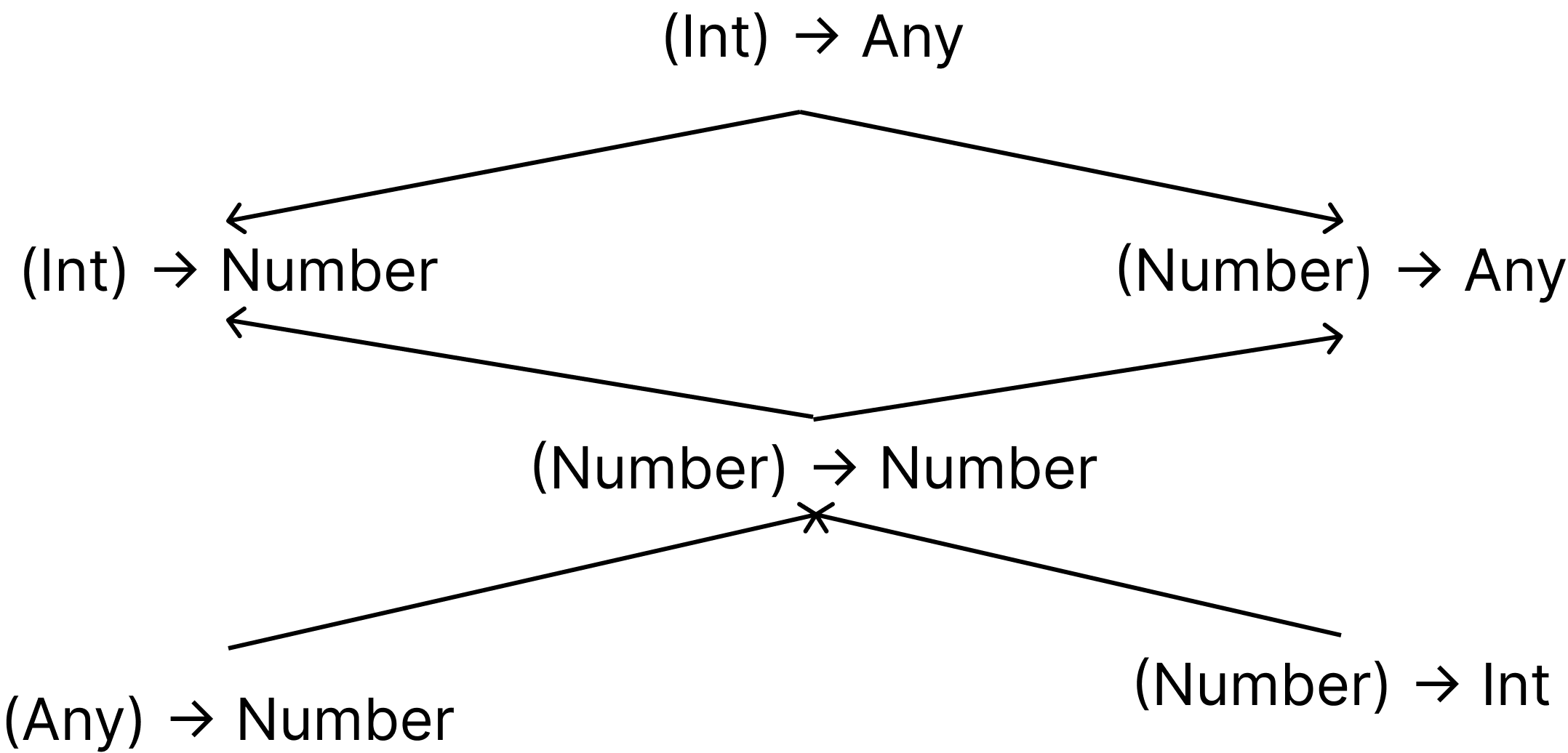
이 그림에서 계층 구조의 아래로 가면, 타이핑 시스템 계층에서 파라미터 타입이 더 높은 타입으로 이동하고, 리턴 타입은 계층 구조의 더 낮은 타입으로 이동합니다.
코틀린 함수 타입의 모든 파라미터 타입은 contravariant입니다. 또한 모든 리턴 타입은 convariant입니다. 다음 그림을 보면 in과 out을 표시했습니다.
(T1in, T2in) -> Tout
contravariant -> convariant함수 타입을 사용할 때는 이처럼 자동으로 variance 한정자가 사용됩니다. 코틀린에서 자주 사용되는 것으로는 convariant(out 한정자)를 가진 List가 있습니다. 이는 variance 한정자가 붙지 않은 MutableList와 다릅니다. 왜 MutableList보다 List를 더 많이 사용하는지, 그리고 어떠한 부분이 다른 것인지는 variance 한정자의 안정성과 관련된 내용을 이해하면 알 수 있습니다.
variance 한정자의 안전성
자바의 배열은 covoriant입니다, 이렇게 만들어진 이유는 다양합니다. 많은 출처에 따르면 배열을 기반으로 제네릭 연산자는 정렬 함수 등을 만들기 위해서라고 이야기 합니다. 그런데 자바의 배열이 convariant라는 속성을 갖기 때문에 큰 문제가 발생합니다.
Integer[] numbers = {1, 4, 2, 1};
Object[] objects = numbers;
objects[2] = "B"; // 런타임 오류: ArrayStoreExceptionnumbers를 Object[]로 캐스팅해도 구조 내부에서 사용되고 있고 실질적인 타입이 바뀌는 것은 아닙니다. (여전히 Integer입니다.) 따라서 이러한 배열에 String 타입의 값을 할당하면, 오류가 발생합니다. 이는 자바의 명백한 결함입니다. 코틀린은 이러한 결함을 해결하기 위해서 Array(IntArray, CharArray 등)를 invariant로 만들었습니다. (따라서 Array<Int>를 Array<Any> 등으로 바꿀 수 없습니다)
파라미터 타입을 예측할 수 있다면, 어떤 서브타입이라도 전달할 수 있습니다. 따라서 아규먼트를 전달할 때, 암묵적으로 업캐스팅할 수 있습니다.
open class Dog
class Puppy: Dog()
class Hound: Dog()
fun takeDog(dog: Dog) {}
takeDog(Dog())
takeDog(Puppy())
takeDog(Hound())이는 covariant하지 않습니다. covariant 타입 파라미터 (out 한정자)가 in 한정자 위치 (예를 들어 타입 파라미터)에 있다면, covariant와 업캐스팅을 연결해서, 우리가 원하는 타입을 아무것이나 전달할 수 있습니다. 즉, value가 매우 구체적인 타입이라 안전하지 않으므로, value를 Dog 타입으로 지정할 경우, String 타입을 넣을 수 없습니다.
class Box<out T> {
private var value: T? = null
// 코틀린에서는 사용할 수 없는 코드입니다.
fun set(value: T) {
this.value = value;
}
fun get(): T = value ?: error("Value no set")
}
val puppyBox = Box<Puppy>()
val dogBox: Box<Dog> = pupyyBox
box.set("Some String") // 하지만 Dog를 위한 공간입니다.
box.set(42) // 하지만 Dog를 위한 공간입니다.이러한 상황은 안전하지 않습니다. 캐스팅 후에 실질적인 객체가 그대로 유지되고, 타이핑 시스템에서만 다르게 처리되기 때문입니다. Int를 설정하려고 하는데, 해당 위치는 Dog만을 위한 자리입니다. 만약 이것이 가능하다면, 오류가 발생할 것입니다. 그래서 코틀린은 public in 한정자 위치에 covariant 타입 파라미터 (out 한정자)가 오는 것은 금지하여 이러한 상황을 막습니다.
class Box<out T> {
var value: T? = null // 오류
fun set(value: T) {
this.value = value;
}
fun get(): T = value ?: error("Value not set")
}가시성을 private로 제한하면, 오류가 발생하지 않습니다. 객체 내부에서는 업캐스트 객체에 convariant (out 한정자)를 사용할 수 없기 때문입니다.
class Box<out T> {
private var value: T? = null
private set(value: T) {
this.value = value
}
fun get(): T = value ?: error("Value not set")
}
convariant (out 한정자)는 public out 한정자 위치에서도 안전하므로 따로 제한되지 않습니다. 이러한 안정성의 이유로 생성되거나 노출되는 타입에만 convariant(out 한정자)를 사용하는 것입니다. 이러한 프로퍼티는 일반적으로 producer또는 immutable 데이터 홀더에 많이 사용됩니다.
좋은 예로 T는 convariant인 List<T>가 있습니다. 지금까지 설명한 이유로 함수의 파라미터가 List<Any?>로 예측된다면, 별도의 변환 없이 모든 종류는 파라미터로 전달할 수 있습니다. 다만 MutableList<T>에서 T는 in 한정자 위치에서 사용되며, 안전하지 않으므로 invariant입니다.
fun append(list: MutableList<Any>) {
list.ad(42)
}
val strs = mutableListOf<String>("A", "B", "C")
append(strs) // 코틀린에서는 사용할 수 없는 코드입니다.
val str: String = strs[3]
print(str)
또 다른 좋은 예로는 Response가 있습니다. Response를 사용하면 다양한 이득을 얻을 수 있습니다. 다음 코드 스니펫 (snippet)에서 어떻게 사용하는지 확인해보겠습니다. variance 한정자 덕분에 이 내용은 모두 참이 됩니다.
- Response<T>라면 T의 모든 서브타입이 허용됩니다. 예를 들어 Response<Any>가 예상된다면, Response<Int>와 Response<String>이 허용됩니다.
- Response<T1, T2>라면 T1과 T2의 모든 서브타입이 허용됩니다.
- Failure<T>라면, T의 모든 서브타입 Failure가 허용됩니다. 예를 들어 Failure<T>라면, T의 모든 서브타입 Failure가 허용됩니다. 예를 들어 Failure<Number>라면, Failure<Int>와 Failure<Double>이 모두 허용됩니다. Failure<Any>라면, Failure<Int>와 Failure<String>이 모두 허용됩니다.
- convariant와 Nothing 타입으로 인해서 Failure는 오류 타입을 지정하지 않아도 되고, Success는 잠재적인 값을 지정하지 않아도 됩니다.
sealed class Response<out R, out E>
class Failure<out E>(val error: E): Response<Nothing, E>()
class Success<out R>(value value: R): Response<R, Nothing>()convariant와 public in 위치와 같은 문제는 contravariant 타입 파라미터 (in 한정자)와 public out 위치 (함수 리턴 타입 또는 프로퍼티 타입)에서도 발생합니다. out 위치는 압묵적인 업캐스팅을 허용합니다.
open class Car
interface Boat
class Amphibious: Car(), Boat
fun getAmphibious(): Amphibious = Amphibious()
val car: Car = getAmphibious()
val boat: Boat = getAmphibious()
사실 이는 contravariant(in 한정자)에 맞는 동작이 아닙니다. 다음 코드를 살펴봅니다. 어떤 상자 (Box 인스턴스)에 어떤 타입이 들어 있는지 확실하게 알 수가 없습니다.
class Box<in T>(
// 코틀린에서는 사용할 수 없는 코드입니다.
val value: T
)
val garage: Box<Car> = Box(Car())
val amphibiousSpot: Box<Amphibious> = garage
val boat: Boat = garage.value // 하지만 Car를 위한 공간입니다.
val noSpot: Box<Nothing> = Box<Car>(Car())
val boat: Nothing = noSpot.value이러한 상황을 막기 위해, 코틀린은 contravariant 타입 파라미터(in 한정자)를 public out 한정자 위치에 사용하는 것을 금지하고 있습니다.
class Box<in T> {
val value: T? = null // 오류
fun set(value: T) {
this.value = value
}
fun get(): T = value // 오류
?: error("Value not set")
}이번에도 요소가 private일 때는 아무런 문제가 없습니다.
class Box<in T> {
private var value: T? = null
fun set(value: T) {
this.value = value
}
private fun get(): T = value
?: error("Value not set")
}이런 형태로 타입 파라미터에 contravariant (in 한정자)를 사용합니다. 추가적으로 많이 사용되는 예로는 kotlin.coroutines.Continuation이 있습니다.
public interface Continuation<in T> {
public val context: CoroutineContext
public fun resumeWith(result: Result<T>)
}
vaiance 한정자의 위치
variance 한정자는 크게 두 위치에 사용할 수 있습니다. 첫 번째는 선언 부분입니다. 일반적으로 이 위치에 사용합니다. 이 위치에서 사용하면 클래스와 인터페이스 선언에 한정자가 적용됩니다. 따라서 클래스와 인터페이스가 사용되는 모든 곳에 영향을 줍니다.
// 선언 쪽의 variance 한정자
class Box<out T>(val value: T)
val boxStr: Box<String> = Box("Str")
val boxAny: Box<Any> = boxStr
두 번째는 클래스와 인터페이스를 활용하는 위치입니다. 이 위치에 variance 한정자를 사용하면 특정한 변수에만 variance 한정자가 적용됩니다.
class Box<T>(value value: T)
val boxStr: Box<String> = Box("Str")
// 사용하는 쪽의 variance 한정자
val boxAny: Box<out Any> = boxStr
모든 인스턴스에 variance 한정자를 적용하면 안 되고, 특정 인스턴스에만 적용해야 할 때 이런 코드를 사용합니다. 예를 들어 MutableList는 in 한정자를 포함하면, 요소를 리턴할 수 없으므로 in 한정자를 붙이지 않습니다. (이와 관련된 내용은 이후에 자세하게 설명합니다.) 하지만 단일 파라미터 타입에 in 한정자를 붙여서 contravariant를 가지게 하는 것은 가능합니다. 이렇게 하면 여러 가지 타입을 받아들이게 할 수 있습니다.
interface Dog
interface Cutie
data class Puppy(val name: String): Dog, Cutie
data class Hound(val name: String): Dog
data class Cat(val name: String): Cutie
fun fillWithPuppies(list: MutableList<in Puppy>) {
list.add(Puppy("Jim"))
list.add(Puppy("Beam"))
}
val dogs = mutableListOf<Dog>(Hound("Pluto"))
fillWithPuppies(dogs)
println(dogs)
// [Hound(name=Pluto), Puppy(name=Jim), Puppy(name=Beam)]
val animals = mutableListOf<Cutie>(Cat("Felix"))
fillWithPuppies(animals)
println(animals)
// [Cat(name=Felix), Puppy(name=Jim), Puppy(name=Beam)]
참고로 variance 한정자를 사용하면, 위치가 제한될 수 있습니다. 예를 들어 MutableList<out T>가 있다면, get으로 요소를 추출했을 때 T 타입이 나올 것입니다. 하지만 set은 Nothing 타입의 아규먼트가 전달될 거라 예상되므로 사용할 수 없습니다. 이는 모든 타입의 서브타입을 가진 리스트 (Nothing 리스트)가 존재할 가능성이 있기 때문입니다. MutableList<in T>를 사용할 경우, get과 set을 모두 사용할 수 있습니다. 하지만 get을 사용할 경우, 전달되는 자료형은 Any?가 됩니다. 이는 모든 타입의 슈퍼타입을 가진 리스트(Any 리스트)가 존재할 가능성이 있기 때문입니다.
'Kotlin' 카테고리의 다른 글
| [이펙티브 코틀린] 4장 추상화 설계 (1) | 2023.07.05 |
|---|---|
| [Kotlin] != null과 ?.let 퍼포먼스 차이가 있을까? (2) | 2023.02.06 |
| [Kotlin] filter, map 호출 순서에 따른 성능 차이 (0) | 2023.02.03 |
| [Kotlin] Collection 관련 함수들 (filter, map, flatmap) (0) | 2023.02.03 |
| [Kotlin] 문자열 Count 하기 (0) | 2022.08.01 |



댓글